

「AI(人工知能)」、「機械学習」、「ディープラーニング(深層学習)」の違いを説明できますか?これらの違いを理解しておくと、「DXプロジェクトの成功に直結する戦略立案」や「効率的なリソース配分」に役立つかもしれません。今回のコラムでは、データ活用のプロフェッショナルであるDATAFLUCTがAI、機械学習、ディープラーニングの違いとビジネスでの活用事例をわかりやすくまとめました。
1.AI・機械学習・ディープラーニングの違いとは?
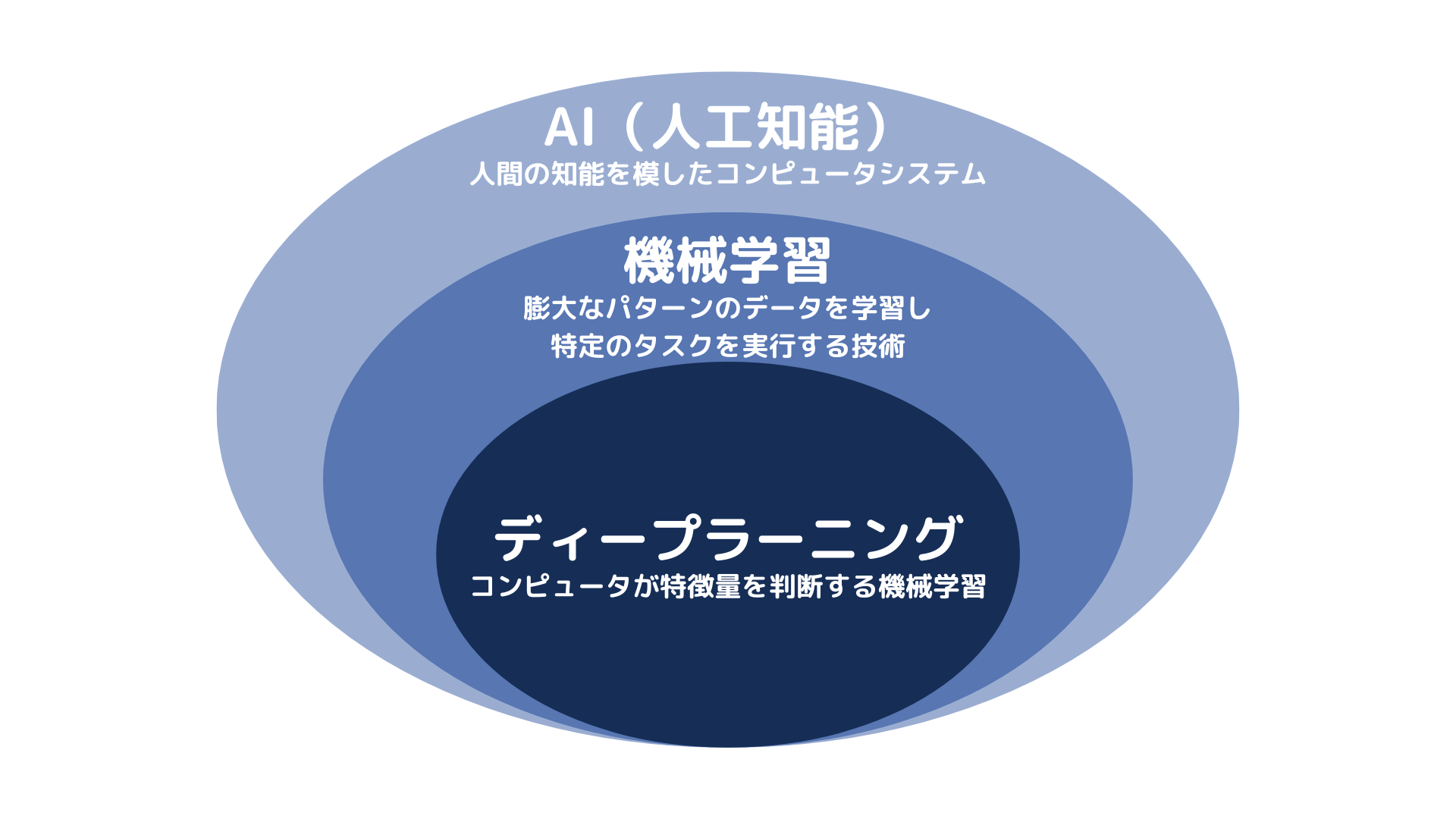
定義と概念の違い
AI(人工知能)、機械学習、ディープラーニングは、現代テクノロジーの中でそれぞれ重要な役割を担っていますが、明確に異なる特性と役割を持っています。
- AI: AIは最も広い概念で、人間の知的活動を模倣し、さらには新たな洞察や成果を生み出すこ技術全般を指します。問題解決、意思決定、言語理解といった高度なタスクを実行する能力を持つシステムが含まれます。
- 機械学習: AIの中核技術であり、データからパターンを学習し、将来の予測や判断を行う技術を指します。機械学習では、アルゴリズムを活用して経験から知識を積み重ね、モデルを改善し続ける仕組みが特徴です。
- ディープラーニング: 機械学習の一部で、ニューラルネットワークと呼ばれる多層構造を用いた高度な学習手法です。ディープラーニングは、大量のデータを処理して複雑な問題を解決する能力を持ち、人間の脳の構造に着想を得たニューラルネットワークを活用しています。画像認識や自然言語処理などの分野で特に力を発揮します。
これらの技術は相互に関連し、組み合わせることで特定の課題に最適なソリューションを提供します。AIは包括的な基盤として、機械学習やディープラーニングを駆使して、より知的で効率的なシステムを構築するための重要な役割を果たします。
適用分野の違い
AI(人工知能)、機械学習、ディープラーニングは、それぞれ異なる適用分野で活用されています。
AIの適用分野
広範な分野での利用が可能で、特に自動化された意思決定や予測、パーソナライズされたサービスの提供などに使われています。例えば、チャットボットや音声アシスタントはAIを活用しており、ユーザーとの対話を通じて情報提供やタスクの実行が行われています。
機械学習の適用分野
一方、機械学習は予測分析・データ分析やパターン認識に特化しており、特に大量のデータから洞察を得るための方法として幅広く利用されています。金融業界では不正検出やリスク管理に、医療分野では診断の補助や患者のデータ分析に活用されています。さらに、マーケティングでは顧客行動の予測やキャンペーンの最適化においてもその力を発揮します。
ディープラーニングの適用分野
ディープラーニングは、機械学習の一部として特に画像認識や音声認識などのタスクでその能力を発揮します。「画像認識」「音声認識」などで高精度を発揮します。たとえば、自動運転車の開発では、「歩行者の検出」や「道路標識の認識」に利用されています。また、医療分野では、画像診断の精度向上に寄与しており、MRIやCTスキャンの画像解析において重要な役割を担っています。
このように、AI、機械学習、ディープラーニングは、それぞれの特性を活かした適用分野が存在し、さまざまな業界で革新を促進しています。これらの技術の進化により、さらに多くの分野で新たなアプリケーションが期待されており、今後もその可能性は広がり続けるでしょう。
2. AIとは?
まず、最も広い概念であるAIについて説明します。
AI(人工知能)とは、人間の知的能力を模倣し、認識、学習、推論、意思決定といったタスクを実行するコンピュータシステムやソフトウェアの種類です。 AIは膨大なデータを処理する能力と計算力を活かし、問題解決能力を向上させます。その基本的な原則は、コンピュータが経験を通じて学習し、より高度なタスクを遂行できるようになることです。
AIは、以下の2つのカテゴリに分類されます。
- 狭義のAI(Narrow AI): 特定のタスクに特化したAIで、顔認識、音声認識、自然言語処理などの分野で使用されています。これらは特定の問題を効率的に解決するために設計されています。
- 汎用AI(General AI): 人間のように多様なタスクをこなすことを目指すAIです。しかし、現時点では研究段階にとどまり、実用化には至っていません。
AIの活用分野は、医療や金融、製造業、エンターテインメントなど多岐にわたります。 例えば、医療分野では診断の精度向上や新薬開発の支援、金融分野ではリスク管理や市場予測に活用されています。特に、ビッグデータ分析や意思決定プロセスの自動化は、AIの進化によって飛躍的に進歩しています。
さらに、AIは機械学習やディープラーニングと連携することで、その能力を最大限に発揮します。これにより、AIは日常生活やビジネスの現場で不可欠な存在となりつつあります。
3. 機械学習とその基本手法
次に機械学習について解説します。
機械学習はAIの一部であり、データから学習して予測や判断を行うためのアルゴリズムと技術をさします。機械学習の目的は、明示的なプログラミングなしに、機械がデータからパターンを学習し、それを基に予測や判断を行えるようにすることです。これにより、人間が勘や経験では予測しにくい複雑な問題も解決可能となります。その方法としては「教師あり学習」「教師なし学習」「強化学習」などさまざまなアプローチがあります。機械学習アルゴリズムがデータからどのように学習するかによって分類されています。自社が対象とする問題の性質と、利用可能なデータをもとに適切なアプローチを選ぶことが重要です。
教師あり学習
教師あり学習では、入力(特徴量)と出力(ラベル)のペアのデータセットを使用してモデルを訓練します。訓練過程で、アルゴリズムは入力から出力を予測する方法を学習します。目的は、新しい未見のデータに対して正確な予測や分類を行うことです。教師あり学習は、主に分類(クラスラベルの予測)と回帰(数値の予測)の問題に使用されます。
(例)
- メールがスパムかそうでないかを識別する(分類)
- 不動産の価格を予測する(回帰)
教師なし学習
教師なし学習では、ラベル付けされていないデータセットを使用します。つまり、出力変数は提供されず、アルゴリズムはデータ内の構造やパターンを自動的に見つけ出す必要があります。データのクラスタリング、次元削減、関連性発見などに使用されます。
(例)
- 顧客セグメントの識別(クラスタリング)
- 大量のデータから重要な特徴を抽出する(次元削減)
強化学習
強化学習では、エージェントが環境と対話しながら行動を学習します。エージェントは、与えられた状態に基づいて行動を選択し、その行動に対する報酬(またはペナルティ)を受け取ります。目標は、報酬を最大化するような方策を学習することです。ゲームプレイ、ロボット制御、レコメンデーションシステムなど、環境からのフィードバックに基づいて最適な行動を決定する必要がある問題に適しています。
(例)
- チェスや囲碁などのゲームでの最適な手の学習
- 自動運転車が環境をナビゲートする方法の学習
機械学習の手法は、問題の特性やデータの性質に応じて多様なアプローチが存在します。これらの手法を適切に選択し、効果的に組み合わせることで、より正確な予測や分類を実現できます。また、これらは個々に使用されることもあれば、実際のプロジェクトでは複数を組み合わせて用いることもあります。データの特性や目標に応じて最適な手法を選択し、適切にチューニングすることが、機械学習の成功において極めて重要です。
4.ディープラーニングの特徴
ディープラーニングは、AIの一部である機械学習の一形態で、特に「ニューラルネットワーク」と呼ばれる多層構造を用いてデータからパターンを学習します。この技術は、人間の脳の神経回路に着想を得て模倣しており、データの特徴を自動的に抽出し、複雑な問題を解決する能力を持っています。ディープラーニングは、画像認識、自然言語処理、自動運転車など、多くの分野で革新的な成果を上げています。従来の機械学習アルゴリズムは、特徴量の選択やデータの前処理に多くの時間を要しましたが、ディープラーニングは膨大なデータセットを利用し、これらのプロセスを自動化することで、より高精度な予測を可能にします。また、計算能力の向上と大量データの利用が可能になったことで、ディープラーニングの研究と応用は急速に進化しています。企業や研究機関は、この強力な技術を用いて新たなビジネスモデルやサービスの開発を進め、社会に多大な影響を与えています。一方で、ディープラーニングモデルの解釈性や透明性の欠如が課題として挙げられることもあり、倫理的な観点からの議論も活発化しています。
ディープラーニングは、従来のアルゴリズムでは解決が難しかった問題に対して驚異的な精度をもたらし、特に画像認識では人間の視覚能力を超える成果を挙げています。例えば、医療分野では、画像診断における病変の検出精度が向上し、早期診断や治療の支援に役立っています。また、音声認識技術を活用したバーチャルアシスタントや翻訳アプリケーションなど、日常生活の利便性を高めるツールの開発も進んでいます。
ディープラーニングのモデル構築において重要なのは、適切なデータセットの準備と、モデルのパラメータ調整です。これにより、モデルはより多様で複雑なデータパターンを学習し、現実世界の問題に対しても頑健なソリューションを提供できるようになります。さらに、ディープラーニングの進化は、生成モデルの開発にも影響を与え、コンテンツ生成やデザイン支援などの新たな応用分野を切り開いています。
5.機械学習の活用事例
機械学習は画像認識、音声認識、自然言語処理、未来予測、売上予測など、幅広いタスクに応用することができます。以下で機械学習がビジネスで役立つシーンを紹介します。
画像認識
画像認識では、画像内のオブジェクトを識別・分類します。畳み込みニューラルネットワーク(CNN)などのディープラーニングモデルは、このタスクで非常に高い精度を達成しています。これらのモデルは、画像のピクセルデータから複雑な特徴を自動的に学習し、物体認識、顔認識、画像分類などのタスクに応用されています。
(例)
- 顔認識システム:異なる照明条件や角度からの顔を正確に識別する
- 医療画像診断:CNNを使用して、X線画像やMRIからがんなどの異常を検出する
自然言語処理
自然言語処理は、人間の言語をコンピュータで理解し、解釈する技術です。テキスト分類、感情分析、機械翻訳、質問応答システムなどがあり、とくにトランスフォーマーモデル(BERT、GPTなど)は、深い文脈の理解に基づいて高度な言語処理を行うことができます。
(例)
- 機械翻訳:文脈全体を考慮して正確な翻訳を生成する
- 文章生成:人間が書いたような流暢で関連性のあるテキストを生成する
未来予測
過去のデータを基にして将来の値やトレンドを予測できます。このタスクには、ARIMA、LSTMなどの機械学習モデルが使用されます。これらのモデルは、株価の動向、気象条件、エネルギー消費など、時間に依存するデータのパターンを学習し、未来の値を予測します。
(例)
- 気象予測:気象データを使用して、未来の天気状態や気温を予測する
- 株価予測:過去の株価データと経済指標を使用して、未来の株価や市場の動向を予測する
売上予測
売上予測では、過去の売上データや関連する外部要因を考慮して、未来の売上を予測します。このタスクには、回帰分析、ランダムフォレスト、勾配ブースティングマシン、LSTMなどの機械学習モデルが使用されます。これらのモデルは、パターンを識別し、複雑な関係をモデル化して、より正確な売上予測を提供します。
(例)
- 小売業の売上予測:過去の売上データ、季節性、プロモーション活動などの情報を使用して、未来の売上を予測する
- 製品の需要予測:過去の販売データ、市場のトレンド、季節性、価格変動などを考慮して、未来の需要を予測する
このように、機械学習は様々な業界で多岐にわたる活用事例を持ち、各分野での課題解決や効率化に大きく貢献しています。
6.DATAFLUCTのAI・機械学習プロジェクト実績
DATAFLUCTは「自社で内製したが上手くいかなかった」「既存の機械学習サービスでは精度が上がらなかった」など、高度な技術を求めるお客様のデータ活用を支援できることが強みです。当社が機械学習によって課題を解決した事例をいくつかご紹介します。
来客数予測
東武鉄道の特急券需要を機械学習で予測。実証実験では、最長14週間後の潜在需要数を30分単位で予測。増便等の判断に活用して、600名以上の潜在需要を掘り起こす
(2023年12月20日発表: https://prtimes.jp/main/html/rd/p/000000206.000046062.html )
梱包サイズ最適化による、物流コスト削減
オルビスと機械学習によるEC梱包サイズ最適化モデルを共同開発。実証実験で注文の約15%でサイズダウンを実現
(2023年7月26日発表:https://prtimes.jp/main/html/rd/p/000000181.000046062.html)
需要予測を活用した、人員・配送最適化
全日食チェーンの物流業務に需要予測システムを導入、人員・配送最適化
(2023年3月15日発表:https://prtimes.jp/main/html/rd/p/000000158.000046062.html)
社内データと外部データを活用した、高精度の食品需要予測
国分グループ本社株式会社 常識にとらわれないAI/機械学習活用で、卸売業に最適な「需要予測モデル」を高精度で実現
(https://service.datafluct.com/case/kokubu)
データサイエンティストがいなくても機械学習を始められる!
機械学習プロジェクトを成功させるためには、エンジニアやデータサイエンティストが必要です。専門的な知識をもとに、データの収集、前処理、モデルの設計と訓練、結果の解釈と実装を進める必要があるためです。
社内にIT人材がいない場合や、自社ではできない複雑な分析に取り組みたい場合は、ぜひDATAFLUCTにご相談ください。ノーコードでデータ収集から活用までが可能なデータプラットフォーム「AirLake」や、最新の機械学習と様々な外部データ活用で高精度な予測が可能な自動需要予測ソリューション「Perswell」を提供する当社ならではの技術と知見で、お客様のデータビジネスをサポートいたします。