

「ChatGPTなどの生成AIを導入したが、期待したほどの成果が出ない」「RAG(検索拡張生成)を試したが、回答の精度が実用に耐えない」……。いま多くの企業が、見せかけのAI活用である「AIエージェント・ウォッシング」という壁に突き当たっています。
2023年に始まった生成AIブームを経て、2026年のメインテーマは、AIが対話を超えて自らタスクを完結させる「AIエージェントの自律実行」へとシフトします。そこで問われるのは、LLM(大規模言語モデル)自体の賢さではありません。AIが正しく判断するための情報をどう整えるか、すなわち「システム設計」の成否です。
本記事では、2026年3月5日(木)に開催された「ITトレンドEXPO2026 Spring」で株式会社DATAFLUCT代表・久米村が解説した、2026年に勝てる「AIエージェント」の実装論をダイジェストで公開します。
AIエージェント実装を成功させるために
「Context Wins」:知能よりも「作業台」の整理が精度を決める

AIエージェントが期待通りに動かない最大の原因は、AIの知能不足ではなく、AIに与える「コンテキスト(文脈)」が散らかっていることにあります。
AI自体が極めて優秀でも、コンテキストが整理されていないと十分に能力を発揮できません。この問題の解決策が「コンテキストエンジニアリング」です。モデル自体の性能向上を待つのではなく、人間もAIも読める形に文章や構造を設計することこそが、AI実装の最重要課題となります。
「非構造化データ」の資産化がハルシネーションを撲滅する
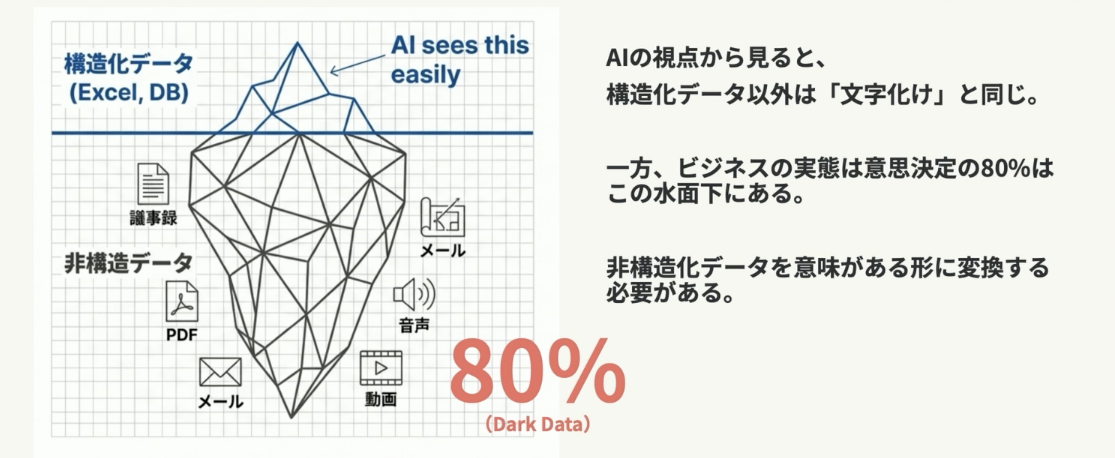
企業内に蓄積されたデータの大半は、PDF、議事録、メール、動画といった、AIがそのままでは読み取れない「非構造化データ」です。ダークデータとも呼ばれるこうしたデータは、AIにとっては「文字化け」しているのと同じなのです。これらを放置したままでは、AIはハルシネーション(嘘)を連発します。
ここで取り組むべきことは、データを意味として扱える単位に処理してからAIに渡すことです。たとえば、会議音声データであれば「会議録音→話者分離→論点抽出→用語の正規化→案件・製品と紐付ける」といった処理が必要となります。
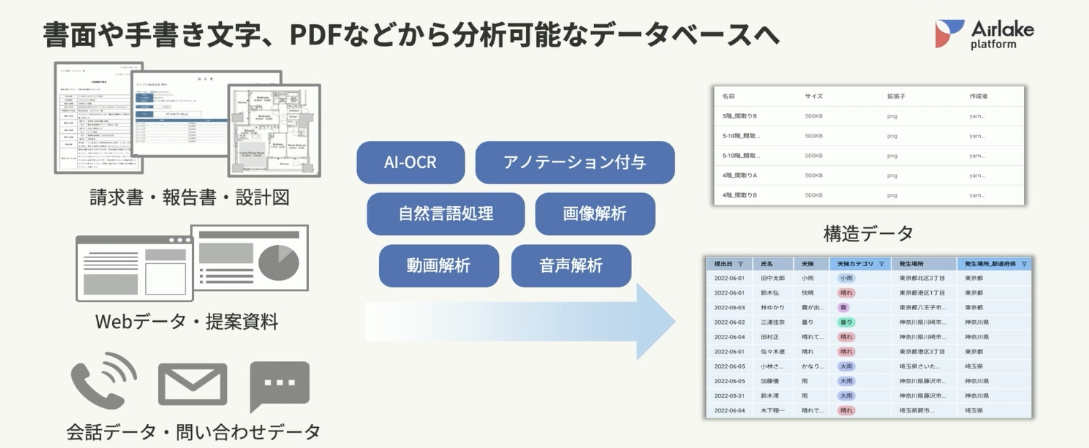
実際にこうした処理を行うための方法として、DATAFLUCTの「Airlake platform」がおすすめです。手書き文字やWebデータも含めてあらゆる情報を簡単に構造化でき、AIが活用できる情報に変えることができます。
最新機能の「ナレッジグラフサーチ」では、DWH層とベクトル検索層(RAG)に加えて、意味のレイヤーである「ナレッジグラフ層」を実装することで、回答の精度をさらに高めています。たとえば、「この設計変更の影響範囲は?」という問いに対し、従来の検索が修正履歴の文書を提示するに留まるのに対し、「ナレッジグラフサーチ」は【設計変更→対象部品→使用製品→納入先→関与部門・工程】までを瞬時に追跡し、“影響パス”として可視化します。
「垂直型AIエージェント」が現場の生産性を爆上げする
汎用的なチャットツールが「個人の生産性」を向上させるものだとすれば、組織全体の変革を担うのは、特定の業務に特化した「垂直型AIエージェント」です。
調達、法務、営業といった部門ごとに、固有のデータとワークフローを学習させたエージェントを配置することが2026年のスタンダードになります。たとえば調達部門であれば、事業予測、RFP(提案依頼書)の作成、価格交渉、発注指示といった一連のプロセスを、複数のAIエージェントがチームとなって自律的に遂行します。
重要なのは、これらすべてのプロセスにおいて「社内データの活用」が不可欠であるという点です。インターネット上の知識(事前学習モデル)だけでは、自社特有の意思決定は支えられません。自社データという燃料を、コンテキストエンジニアリングという設計図で動かすことで、初めて実戦で使えるエージェントが誕生するのです。
現実的なAIエージェント実装のための「2つの重要戦略」
コンテキストを整えた上で、実際にAIを業務に組み込む際には、以下の2つのアプローチが推奨されます。
スモールモデル・オーケストレーション
「何でもできる巨大な1つのモデル」に頼るのではなく、専門スキルを持つ「小さなモデル」を複数組み合わせる設計です。小さなモデルを協調させることで、処理速度の向上、コストの抑制、そして何より回答精度の安定化という大きなメリットを享受できます。
段階的な権限付与と承認プロセス
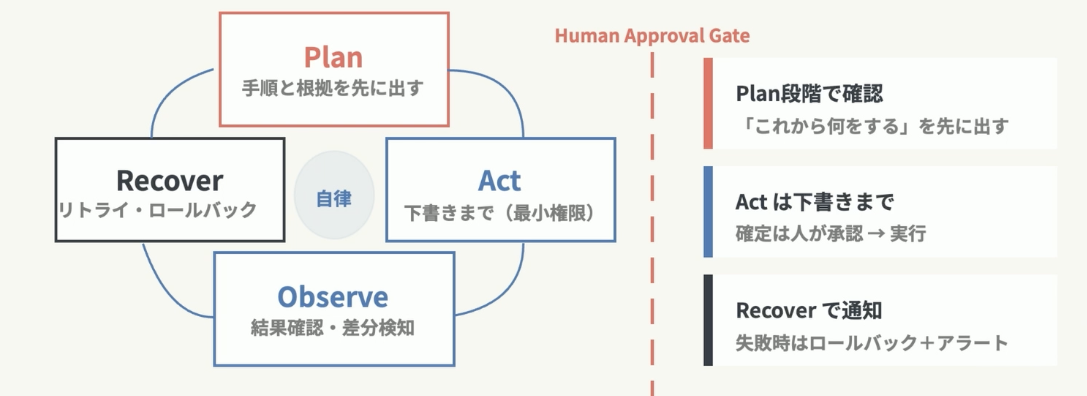
AIに最初からすべての実務(書き込み権限など)を任せず、まずは「AIがプランを作成 → 人間が承認 → AIが下書きを作成」というステップを確実に踏むアーキテクチャを構築しましょう。最終的な書き込み(実行)に至るまでのハードルを段階的にクリアする設計が、組織内での信頼を勝ち取る近道です。
DATAFLUCTでは、これらの設計思想を具現化したサービスをすでに展開しています。
- Airlake BI Agent: データサイエンティストの業務を代行するエージェント。自然言語での問いかけに対し、SQLの生成から集計、グラフ作成までを対話だけで完結させます。
- Airlake Copilot Agents: 資料の収集、要約、リサーチなどを複数のAIがチームで分担し、ワークフローとして自動実行します。あなたが眠っている夜間や休日であっても、並列処理でタスクを回し続けることが可能です。
2026年を「AIエージェント実装元年」に
AIはもはや、単なる「便利な道具」から、自律的に判断し動く「最強の同僚」へと進化しています。
そのための第一歩は、社内に眠る膨大な非構造化データを整理し、AIが読める形に「資産化」することです。コンテキストエンジニアリングを徹底し、ビジネスインパクトの大きい「垂直型」から導入を進めていく。このプロセスを経て、企業は真の自律化時代を迎えることができます。
2026年、競合が「AIエージェントごっこ」で足踏みしている間に、データを資産に変え、自律的な組織への変革を加速させていきましょう。
実装に向けた具体的なステップやコスト感、自社データでの実現可能性については、ぜひDATAFLUCTへご相談ください。
【アーカイブ視聴・お問い合わせ】
セミナー動画をフルで見たい方はこちら
https://datafluct.com/seminar/s0007/
自社データでの活用を相談したい方はこちら
https://datafluct.com/contact/
「うちのデータでもエージェント化できる?」「導入コストはどのくらい?」など、貴社の状況に合わせた個別のご相談を承ります。